[논문 리뷰] Parameter-Efficient Transfer Learning for NLP
목차
요약
Adaptive module을 활용한 transfer learning 기법을 제안
INTRO
기존: Transfer from Pretained models has showed strong performance on many downstram tasks of NLP
- downstream task란 자연어 처리의 번역, 문맥 파악, 다음 문장 예측, Q&A 등의 과제들을 의미
- 예를 들어, BERT는 다양한 자연어 태스크에 대해서 pretrained 모델로 효과적

Figure1. 정확도(Accuracy)와 파라미터/태스크 개수의 trade-off를 보여주는 그림. y축은 Full-fine tuning 성능으로 normalized 된 accuracy이다. Fine-tuning의 경우 학습 파라미터/태스크 개수가 많아질 수록 성능이 떨어진다. 이에 반해 위의 모델에서 제시한 Adapter모델은 이에 영향 받지 않고 높은 성능을 보임을 알 수 있다.
무엇이 문제인가? 온라인 환경에서 모델을 운영하는 일
" In this paper we address the online setting, where tasks arrive in sequence."
온라인 세팅은 실제 모델이 배포되어 상용화되고 있는 클라우드와 같은 환경이다.
-> 모델에 여러 사용자들은 연속적으로 다양한 유형의 태스크 수행을 요청한다.
예시: 실시간 사용자 Q&A시스템
이 시스템은 사용자로부터 질문을 계속해서 받고, 다양한 질문 유형에 따라서 적절한 답변을 제시해야 한한다.
시스템이 어떻게 작동할까?
사용자가 첫 번째 질문을 보내면, 모델은 그 질문에 대해 학습을 하고 답변을 생성합니다.이후, 또 다른 사용자가 새로운 질문을 보내면, 시스템은 이 새로운 질문에 대해서도 학습하고, 필요한 경우 이전 질문과 관련된 정보들을 활용해 적절한 답을 제공합니다.
이 환경에서는 사용자가 보내는 질문이 스트림 형태로 지속적으로 도착하는 작업입니다. 따라서 모델은 미리 모든 질문을 학습하지 않고,
새로운 질문이 들어올 때마다 그에 맞추어 업데이트되거나 대응할 수 있어야 합니다.
이때, 모델은 사용자들의 다양한 태스크를 미리 학습할 수 없다. 따라서,
1) 다양한 태스크가 들어올 때마다 빠르고, 유연하게 적절한 답변을 만들고,
2) 직전 질의 응답을 기반으로 모델을 실시간 업데이트 해야 된다.
특정 task에 맞춰서 학습하는 방법은 Fine-tuning 모델도 있다.
그러나 학습하는 파라미터가 많고, 새로운 태스크에 유연하게 대응하지 못한다. -> 그래서 우리는 새로운 Adapter module을 제안한다.
제안 아이디어: Adative transfer learning technology
특징: compact(간단;적은 수의 파라미터로 각 태스크를 해결) + extensible(확장 가능; 기존 파라미터를 확장하여 새로운 태스크를 해결하는데 기여)
- Compact models are those that solve many tasks using a small number of additional parameters per task.
- Extensible models can be trained incrementally to solve new tasks, without forgetting previous ones.
배경 지식: feature-based, fine-tuning
2가지 모두 transfer learning 기법이다. Pretrained 모델 레이어 일부를 학습하는지에 대해 차이가 있다. feature-based(Feature extraction)는 사전학습 모델의 히든 레이어를 모두 freeze하고 새로운 목적에 맞춰 최종 레이어만 변형한다. 단순히 데이터를 모델에 통과 시켜서 피쳐를 추출한다고 생각하면 된다. 그러나, fine-tuning은 Pretrained 모델의 일부 레이어를 선택적하여, custom 데이터에 맞게 웨이트를 다시 재학습시킨다.

fine-tuning이 feature-based 보다 parameter efficient 하다고 한다.
Adapter Tuning Strategy
사전 학습 모델 레이어 간 어댑터 모듈을 추가한 구조이다. 기존 fine-tuning은 보통 뉴럴 네트워크의 마지막 레이어(top layer)에 새로운 레이어를 추가하는 방식으로 구성된다. 그 이유는, upstream task와 down-stream task의 레이블 공간과 로스 형태(크기)가 다르기 때문이다. 이와 다르게 Adapter는 새로운 태스크를 학습하기 위해서, 네트워크 전반에 걸친 모델 구조를 변경한다.
아래 그림(왼쪽)과 같이 레이어간 Adapter 모듈을 추가한다. 기존 레이어의 웨이트는 고정되어 있되, 어댑터 모듈 내의 웨이트만 학습된다. 따라서, 다양한 태스크들은 기존 레이어 웨이트를 공유하되, 적은 파라미터 개수로 새로운 태스크에 유연하게 대처할 수 있다는 장점이 있다.

트랜스포머에 어댑터 구조를 다음과 같이 반영한다.
[특징]
- Small num of features
- a near-identity initialization: 신경망의 가중치를 학습 초기 단계에서 거의 변형되지 않도록 하는 초기화 방법이다. 이를 통해서, Adapter learning 이 시작될 때, 원래 네트워크의 가중치들이 영향을 받지 않는다.
Feature-based, Fine-tuning과 차이점
기호 정리
𝑤: Pretrained 모델의 학습 파라미터(vector)
𝑣: 새롭게 학습해야할 파라미터(vector)
𝜑_𝑤: 사전학습된 모델(Neural network)
x: 인풋 데이터
Feature-based learning: 𝜒_𝑣(𝜑_𝑤(x))
: 𝜒_𝑣은 단순히 출력만 바꿔주는 final layer라고 생각하면 된다. 즉, 기존 사전 학습된 네트워크 𝜑_𝑤의 결과를 새로운 태스크의 출력(𝜒_𝑣)에 맞게 변환한 결과이다.
Fine-tuning: 𝜑'_𝑤'(x)
사전 학습된 파라미터 자체를 변형, 즉 모델 함수 자체를 변형한다. - 𝜑_𝑤(x) -> 𝜑'_𝑤'(x)
Adapter: 𝜓_{𝑤,𝑣}
𝑤는 고정하되, 새로운 태스크에 대한 가중치 𝑣만 업데이트한다.
---------------------------------------------
장점
즉, 기존의 파인튜닝 기법이나 Feature-based learning의 경우에는 새로운 태스크에 최적화 하기 위해 (v를 학습하기 위해) |w| 사이즈의 파라미터를 학습해야했다면, Adapter에서는 v만 학습하면 되므로 parameter-efficient 하다는 것이다.
Adapter는 multi-task learning과 continual learning의 특성을 가지고 있되, 다른 점도 있다.
- multi-task learning은 한 번에 여러 개의 access를 동시에 처리한다 <-> 그러나 Adapter는 연속된 입력을 받는다.
- continual learning은 연속적인 입력 시퀀스를 통해 학습을 진행한다. 그러나, 새로운 입력이 들어왔을 때 이전의 입력을 잊는 한계점이 있다. <-> 그러나 Adapter는 기존 학습 내용을 기억하고 있다.
효능: 3%의 task-specific parameter를 통해 똑같은 성능을 보장함. 즉 compact 하면서 extensive한 모델이다.
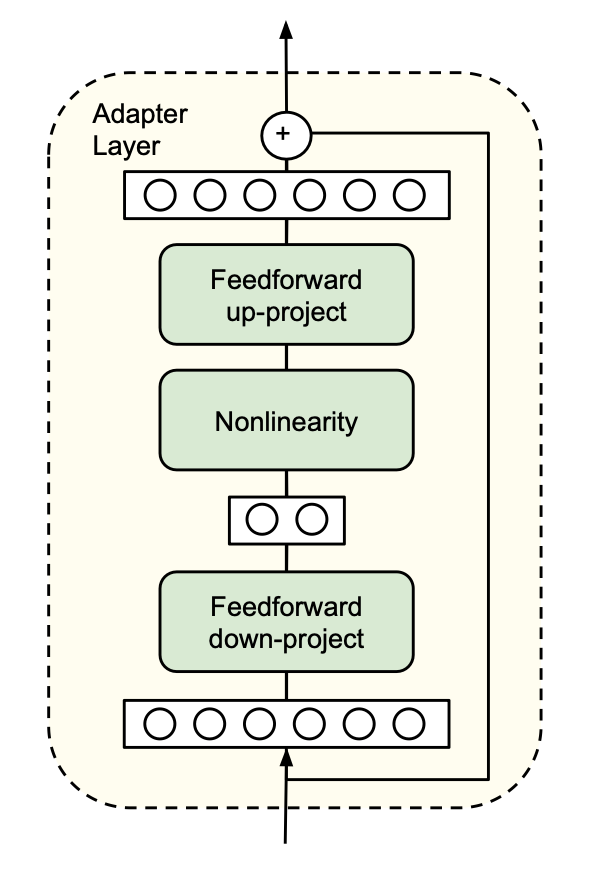
Adapter strategy 구조의 핵심
구성) Feed-forward down - Nonlinearity - Feedforward 레이어
핵심 기능: 차원을 축소했다가 다시 늘림
1. FeedForward down project: 입력 차원을 (d)로 축소, 핵심만 추출
- bottle-neck 구조를 활용
2. Non-linearity (e.g. GELU, ReLU)
- 인코더와 디코더의 스킵 커넥션 역할
3. Feedforward up project: 입력 차원을 다시 원래 늘림
--------
질문 리스트
Q. sequential 한 요청?
- 각 sequence 별로 task가 다르다고 생각 -> sequence가 끝나고 기존 학습 내용이 필요할 수도 있고, 안할 수도
- 이런 sequential 구조에 최적화된 모델이다.
Q. 수학적으로 어떤 의미가 있는지 궁금하다...
- sally 퍼실님한테 한 번 더 물어보면 좋을 것 같다.